COLING 2022: Key Insights on NLP and Evaluation Metrics
Written on
Overview of COLING 2022
COLING 2022 took place in mid-October in Gyeongju, South Korea, gathering a vast array of research with 2,253 submissions from across the globe. Out of these, only 632 (28.1%) were accepted for publication after thorough reviews conducted by 1,935 reviewers and 44 senior area chairs.
In this discussion, I highlight six notable papers that particularly captured my attention.
Layer or Representation Space: Enhancing BERT-based Metrics
The paper by Doan Nam Long Vu (Technical University of Darmstadt), Nafise Sadat Moosavi (The University of Sheffield), and Steffen Eger (Bielefeld University) investigates the robustness of recent metrics for natural language generation, such as BERTScore, BLEURT, and COMET. While these metrics typically show strong correlation with human evaluations on standard benchmarks, their performance in less-represented styles and domains remains questionable.
The authors discovered that BERTScore lacks robustness when subjected to character-level alterations. For example, minor character insertions or deletions can lead to a marked decline in correlation with human assessments.
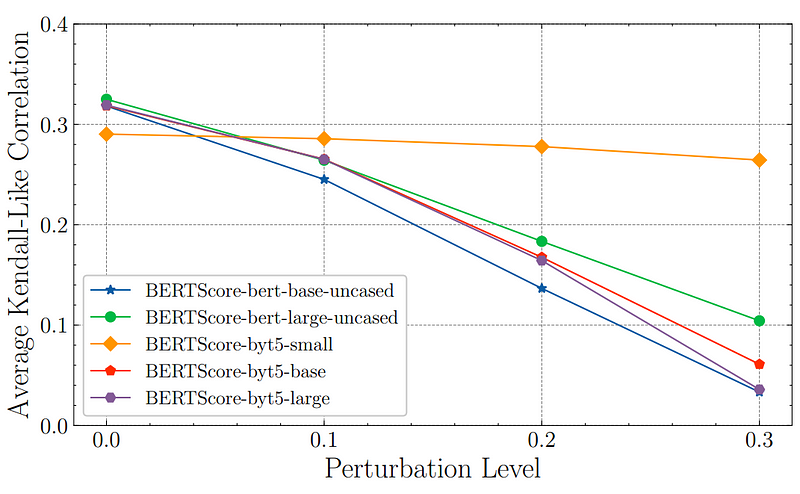
By utilizing models equipped with character embeddings, such as ByT5, instead of traditional BERT models, the authors demonstrated that BERTScore's robustness improves, particularly when using embeddings from the initial layer. This adaptation could enhance evaluation metrics for user-generated texts, which often contain grammatical errors, making this paper a significant contribution to the field.
The paper received an outstanding paper award at the conference.
Grammatical Error Correction: Progress and Pitfalls
In a thought-provoking study by Muhammad Reza Qorib and Hwee Tou Ng from the National University of Singapore, the authors reveal that current grammatical error correction (GEC) systems surpass human performance on standard benchmarks. Yet, these systems still struggle with correcting unnatural phrases, lengthy sentences, and complex structures.
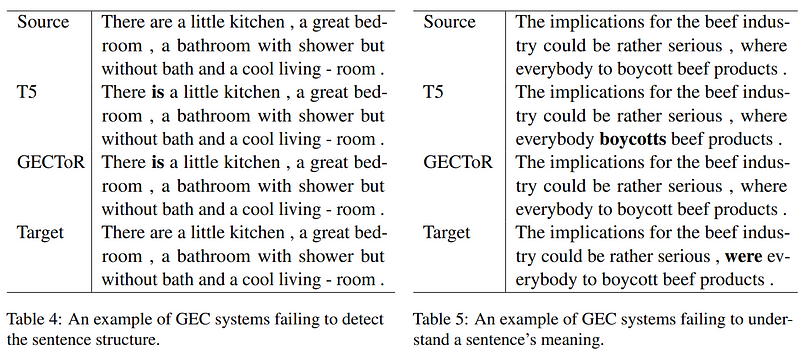
The authors argue that GEC systems have not yet achieved the level of human performance, as current benchmarks may be too simplistic. They advocate for the development of new benchmarks that focus on more challenging grammatical errors, thereby motivating further research to enhance GEC systems.
Machine Reading: Understanding Language Complexity
The research conducted by Sagnik Ray Choudhury and colleagues from the University of Michigan and University of Copenhagen presents evidence that large language models lack true understanding of language. Their evaluations on linguistic skills, including comparison and coreference resolution, indicate that these models rely heavily on lexical patterns rather than the nuanced understanding exhibited by humans.
This paper underscores the limitations of current models and illustrates their struggles with counterfactual perturbations, suggesting that these models may be more about memorization than comprehension.
The first video titled "COLING 22 KGE4NLP tutorial" delves deeper into these concepts.
Resource-Rich Machine Translation: A Dual Approach
Changtong Zan and co-authors explore the intersection of pre-trained language models (LM) and random initialization in resource-rich machine translation. Their findings reveal that while pre-trained models do not significantly enhance translation accuracy, they contribute to smoother loss landscapes and improved lexical probability distributions.
The authors propose a combination of both techniques to optimize performance for various translation scenarios, indicating ongoing efforts to integrate pre-trained models in machine translation.
Alleviating Attention Head Disparities in Neural Translation
Zewei Sun and colleagues introduce a novel approach to address the unequal significance of attention heads in machine translation. By implementing a "head mask," they aim to equalize training across attention heads, observing slight improvements in BLEU scores across various language pairs.
Despite the modest gains, their methods offer a simple solution that can be easily integrated into existing machine translation frameworks.
Unsupervised Paraphrase Generation: A New Frontier
The study led by Xiaofei Sun and others proposes a fresh perspective on paraphrase generation through unsupervised machine translation (UMT). By utilizing domain-level clustering instead of traditional source-target language pairs, the authors successfully generate paraphrases without the constraints of supervised datasets.
Their extensive evaluations demonstrate the efficacy of this method, although further clarification on the importance of clustering and comparisons with prior approaches would enrich the discussion.
Conclusion
The insights presented here represent just a fraction of the 632 papers discussed at COLING 2022. I encourage you to explore the complete proceedings for a broader understanding of recent advancements in natural language processing. For additional insights into machine translation, consider checking my AMTA 2022 highlights.
The second video titled "COLING 22 KGE4NLP tutorial - hands-on session" provides practical demonstrations of the concepts discussed.