Navigating Algorithmic Risks: Insights from 62 Studies on Big Tech
Written on
In the United States, there is currently no federal agency dedicated to safeguarding the public against harmful algorithms.
Consumers can buy eggs, receive vaccines, and drive on highways with the assurance that various systems are in place to ensure safety: the USDA inspects eggs for salmonella, the FDA evaluates vaccines for safety and efficacy, and the NHTSA ensures that highway designs accommodate high-speed travel.
However, when we search on Google or browse products on Amazon, how much do we understand about the safety of the algorithms that power these services? While some regions are moving towards regulatory oversight, we still lack an “FDA for algorithms.”
To illustrate the potential dangers, I recently conducted a literature review encompassing 62 studies that reveal how algorithms from large tech companies can harm the public. Examples include predatory ads appearing in Google searches or misleading health product recommendations on Amazon. Although governmental oversight is still in the works, researchers and journalists have made significant strides in documenting these algorithmic harms.
These “algorithm audits” are becoming increasingly crucial as algorithms infiltrate more aspects of our digital lives.
In this post, I will outline the four main categories of algorithmic harms identified in my literature review (the full preprint is available for those interested):
- Discrimination: Instances where Amazon's résumé screening algorithm showed bias against women.
- Distortion: Situations in which Amazon's search algorithm promoted misleading health products for vaccine-related queries.
- Exploitation: Cases where Google’s advertising system took advantage of sensitive data related to substance abuse for targeted ads.
- Misjudgment: Occurrences where Facebook’s AI mistakenly suspended ad campaigns for small businesses.
Demonstrating these algorithmic issues is no simple feat. When an algorithm's task is straightforward, such as alphabetically sorting a list or summing a column in an Excel sheet, there is a “correct” answer that allows for easy verification of its functionality.
Yet, the algorithms behind many of today’s technologies often lack definitive “correct” responses. For instance, consider the algorithm that curates your YouTube video suggestions or determines which articles appear on Google News. These “subjective decision makers,” as Zeynep Tufekci puts it, can yield various harmful outcomes, and there is no singular correct answer to verify whether an algorithm is functioning as intended, let alone if it is safe or effective. In the studies I reviewed, researchers employed a range of “safety checks” to audit publicly accessible algorithms.
Algorithms that Discriminate
Social issues often find their way into algorithmic systems. While more individuals, including lawmakers like Alexandria Ocasio-Cortez, are beginning to recognize how these systems can exacerbate discrimination, this awareness required considerable effort to gain traction. Certain studies have played a pivotal role in this shift.
Early Evidence of Algorithmic Discrimination
Two of the most influential studies in my literature review investigated discrimination within Google's search algorithm. In a 2013 study, Latanya Sweeney analyzed ads displayed for searches using names perceived as black versus those perceived as white. A clear pattern emerged: criminal record ads were shown for black-sounding names (for instance, a search for “Latanya Sweeney” returned an ad questioning if she had been arrested).
Conversely, searches using white-sounding names, such as “Kristen,” did not yield any ads referencing arrests or criminal records.
That same year, Safiya Noble published another significant study addressing discrimination in Google search. In her acclaimed book, Algorithms of Oppression, Noble recounts how her research began in 2010 while she sought interesting content for her stepdaughter and nieces. She was alarmed to find that five of the top ten search results were sexualized or pornographic.
Noble succinctly explains the impact of discrimination in search results:
> “Online racial disparities cannot be ignored in search because it is part of the organizing logic within which information communication technologies proliferate, and the Internet is both reproducing social relations and creating new forms of relations based on our engagement with it.” (Safiya Noble, 2013)
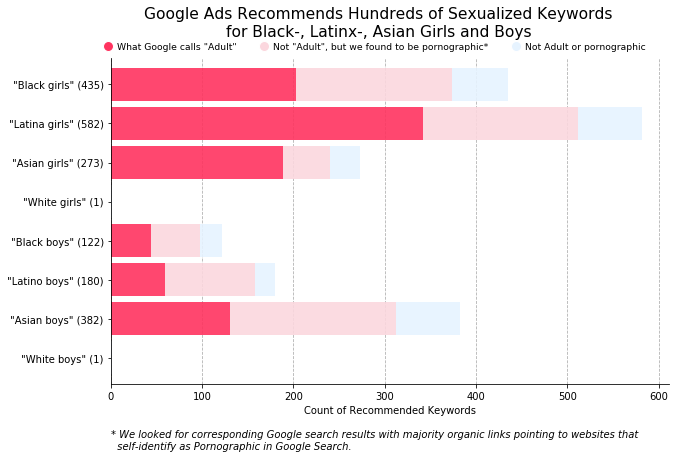
While many technologists consider such issues mere “glitches” that can be resolved, Ruha Benjamin, in her book Race After Technology, argues that these glitches highlight larger systemic problems. This assertion is supported by ongoing evidence: seven years after Noble's findings, The Markup revealed that Google continued to make the same critical error on its advertising platform. Below is a chart from their investigation of Google’s “keywords planner” feature:
Computer Vision and Beyond
Another foundational study on algorithmic discrimination was the “Gender Shades” audit by Joy Buolamwini and Timnit Gebru. This research unveiled discrepancies in facial recognition technologies developed by Microsoft and IBM, where light-skinned males were often accurately identified, while darker-skinned females were frequently misidentified. A subsequent study by Buolamwini and Inioluwa Deborah Raji confirmed performance disparities across various commercial systems, although some systems showed improvement.
In reviewing the literature, these initial audits set the stage for continued scrutiny of algorithmic discrimination. More recently, a 2020 audit by researchers Joshua Asplund, Motahhare Eslami, Hari Sundaram, Christian Sandvig, and Karrie Karahalios discovered that emulating Caucasian users led to an increase in housing-related ads, while emulating African Americans resulted in more ads for predatory rent-to-own schemes.
As anxiety about employment rises in the U.S., the public should also be concerned about discrimination in hiring algorithms. A 2019 study by Maria De-Arteaga and colleagues found significant gender disparities in employment classification systems. Additionally, Sahin Cem Geyik, Stuart Ambler, and Krishnaram Kenthapadi demonstrated a method to enhance gender representation in LinkedIn’s talent search system.
All of this remarkable research only scratches the surface: my literature review identified 21 studies focused on discrimination, and there are likely many others that I did not cover! For more details, check out the full paper and/or the list of discrimination audits.
Algorithms that Distort
Numerous algorithm audits reference a study indicating that 39% of undecided voters may change their voting preferences based on the search results they encounter. For example, if 100 undecided voters search for candidate Tonald Drump and the results favor him, approximately 39 voters may also lean towards Drump. This phenomenon exemplifies distortion, a significant focus of studies examining the gatekeeping influence of algorithms.
The “search engine manipulation effect” mentioned above (from the research of Robert Epstein and Ronald E. Robertson) has prompted many audits to investigate potential partisan biases in search engines. This is a complex issue without a straightforward “yes or no” answer, especially given the challenges in quantifying “partisanship.” Here are three noteworthy studies on the topic:
- A 2018 study by Ronald E. Robertson and others found that news displayed on Google leaned slightly left but also indicated that Google’s ranking algorithm shifted the overall lean of Search Engine Results Pages slightly to the right.
- Research conducted by Stanford during the 2018 midterm elections observed “virtually no difference” in the partisan distribution of sources between queries for Democrats and Republicans.
- A study by my colleague Daniel Trielli and advisor Nick Diakopoulos found that while the “Top Stories” box contained more articles from left-leaning sources, this reflected a broader trend across the internet based on a vast database of news known as GDELT.
Echo Chambers
Partisan distortion is merely one of several variations being explored by researchers. Distortion also encompasses studies on “echo chambers” or “filter bubbles” that purportedly restrict users to content they already agree with. Contrary to popular belief, there is limited empirical evidence supporting the existence of filter bubbles. In fact, evidence suggests that internet users encounter a greater diversity of sources on algorithm-driven platforms. Algorithms do personalize the online experience, but not to the extent of creating a bubble.
An early personalization audit by Aniko Hannak and colleagues found that, on average, only 11.7% of search results were personalized, with personalization occurring more frequently for queries related to “gadgets” and “places.” A later study by Hannak, Chloe Kliman-Silver, and others revealed that most personalization stemmed from the user’s location. My lab's recent research found that even when users searched using different partisan terminology (e.g., “beto orourke pros” versus “lies by beto orourke”), Google exhibited a mainstreaming effect, displaying similar and consistent results.
However, mainstreaming can lead to the concentration of attention on a limited number of sources, as demonstrated in a study of Apple News. This becomes particularly problematic when it results in the exclusion of certain sources. For instance, a recent audit by Sean Fischer, Kokil Jaidka, and Yphtach Lelkes found that Google frequently excludes local news from search results. By diverting traffic away from local journalism, Google may be contributing to the declining health of local news outlets and the emergence of “news deserts” across the U.S., as explored by Penny Muse Abernathy.
Misinformation
Another aspect of distortion relates to the spread of low-quality media, including false information and sensationalist content. (The term “fake news” has become less useful as it has been appropriated by various political and extremist groups.) One audit, led by Rediet Abebe, discovered that search results for HIV/AIDS often suggested “natural cures” that have been proven ineffective or even harmful.
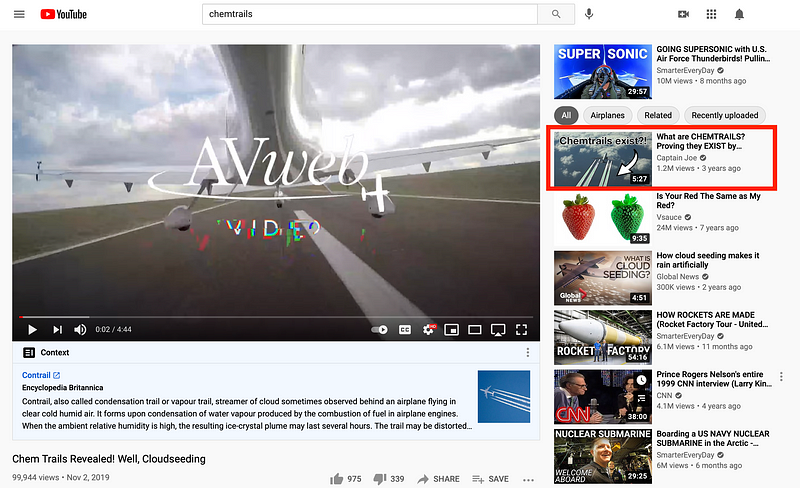
Researchers have also identified misinformation rabbit holes on platforms like YouTube, although some, such as the “chemtrails” rabbit hole, appear to have been addressed. A quick search on YouTube revealed that both the search results and recommended videos provided factual explanations:
In total, the literature review included 29 audits focused on distortion, indicating this is just a snapshot of the ongoing research. The complete list is available here, including new studies not yet published in the paper.
Algorithms that Exploit
The notion that “big tech profits off your data” has gained traction recently, with several audits examining how this dynamic plays out. Much of the public discourse centers around invasive data collection, and studies indicate that this is a legitimate concern. One research project led by José González Cabañas found that Facebook's explanations were often misleading, obscuring how the platform exploited sensitive attributes for targeted advertising. A similar case was documented in a study by Amit Datta on Google.
Another form of exploitation involves the labor needed to generate content for algorithmic systems. For instance, one study revealed that without user-generated content from platforms like Wikipedia, Twitter, and StackOverflow, Google's search engine would be far less effective. A follow-up study by my colleague Nick Vincent found that Wikipedia content appears in 81% of result pages for trending searches, and in 90% of result pages for contentious topics like the “Death Penalty” or the “Israeli-Palestinian Conflict.” This study also highlighted Google's heavy reliance on news media for search results, even as Google fails to adequately compensate publishers.
This exploitation forms the basis for viewing data as a form of labor and considering how platforms could compensate individuals for their contributions. For example, revenue generated from user data could be directed towards public goods such as parks, WiFi, and infrastructure, or simply distributed to users, as the Brave browser does.
Algorithms that Misjudge
Misjudgment stands apart from the other behaviors discussed, acting as a broad meta-category. In the literature review, I suggest that future audits should aim to focus on more specific problematic behaviors to clarify the risks and harms associated with algorithms. Nevertheless, there were several intriguing studies on general “misjudgment” worth noting.
One common form of misjudgment occurs in advertising platforms, which many users may recognize when pondering, why am I seeing this ad? It turns out that algorithmic systems often make incorrect inferences about user interests or demographic characteristics for targeted advertising. A 2019 study led by Giridhari Venkatadri discovered that approximately 40% of targeting attributes on platforms like Epsilon and Experian were “not at all accurate.” For example, some users classified as corporate executives were actually unemployed.
These inaccuracies could signal the existence of a potential “digital advertising bubble,” recently described by author Tim Hwang as “the subprime attention crisis.” In essence, advertisers might reconsider their spending on targeted ads if they were aware that 40% of targeting features were misleading.
Conclusion
New technologies invariably introduce new risks to the public. Through this literature review, I identified 62 studies (and counting) that underscore the dangers posed by the algorithms that drive Google, Amazon, Facebook, and other major tech platforms. From discrimination to distortion, exploitation, and misjudgment, researchers have demonstrated that algorithmic systems can and do inflict harm on the public, not merely in hypothetical scenarios but in our everyday lives.
The concerning reality is that algorithmic systems can and do harm the public, not just in theoretical contexts but in our actual world.
On a positive note, as Arundhati Roy eloquently stated, “another world is not only possible, she is on her way.” We have the opportunity to steer the course by collaborating as a coalition of users, researchers, journalists, and other stakeholders. Together, we can design, develop, and utilize systems that prioritize the public good over corporate interests.
There is much work ahead, and numerous challenges to overcome, but united, we can establish healthier relationships with our technology.