<Examining AI's Convergence: The Platonic Representation Theory>
Written on
The Platonic Representation Hypothesis raises intriguing questions about the evolution of artificial intelligence models and whether they are moving towards a shared understanding of reality. A recent publication from MIT asserts that AI models, particularly deep neural networks, are indeed converging, even when trained on disparate datasets and for varied applications. The authors state, “We argue that representations in AI models, particularly deep networks, are converging.”
But what factors contribute to this convergence across models with differing architectures and goals?

1. The Platonic Representation Hypothesis
> The authors of the paper argue that there is an increasing resemblance in how data points are represented across various neural network models, transcending differences in architecture, training goals, and even data types.

1.1 Introduction
The central thesis of the paper posits that models from diverse origins and modalities are gravitating towards a shared representation of reality — a joint distribution of the real-world events that generate the data used for training these models. The authors contend that this shift towards a "platonic representation" is influenced by the inherent structure and nature of the data, coupled with the increasing complexity and capabilities of the models themselves. As these models engage with a wider array of datasets and applications, they necessitate a representation that encapsulates the fundamental characteristics common to all data types.
1.2 Plato’s Cave
The paper draws an analogy from Plato’s Allegory of the Cave to illustrate how AI models are theorized to develop a unified representation of reality. In this allegory, prisoners confined in a cave only perceive shadows of real objects cast upon a wall, mistaking them for reality. In contrast, the true forms exist outside the cave and represent a more genuine reality than the shadows seen by the prisoners.

2. Are AI Models Converging?
AI models of varying sizes, built on distinct architectures and trained for different tasks, are showing trends of convergence in their data representation methods. As these models increase in scale and complexity, and as the datasets they process become larger and more varied, their data processing techniques begin to align. Do models trained on different modalities, such as vision or text, also converge? The answer appears to be affirmative.
2.1 Vision Models that Talk
This alignment occurs across both visual and textual data. The paper notes that while this theory primarily focuses on these two modalities, it does not encompass others like audio or robotics. One supporting example is LLaVA, which demonstrates how visual features can be mapped to language features using a two-layer MLP, achieving state-of-the-art performance.
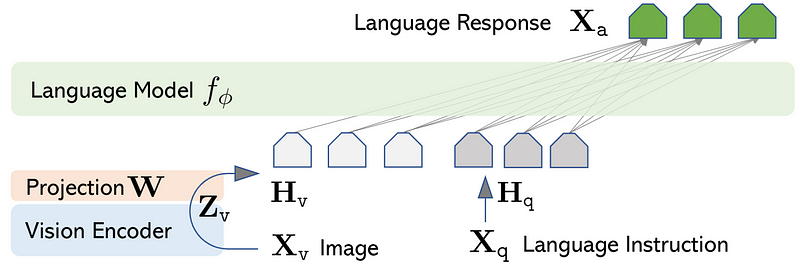
2.2 Language Models that See
Another noteworthy example is "A Vision Check-up for Language Models," which investigates how well large language models comprehend and process visual data. This study employs code as a bridge between images and text, revealing that LLMs can generate images via code that, while not entirely realistic, still contain sufficient visual information to train vision models.
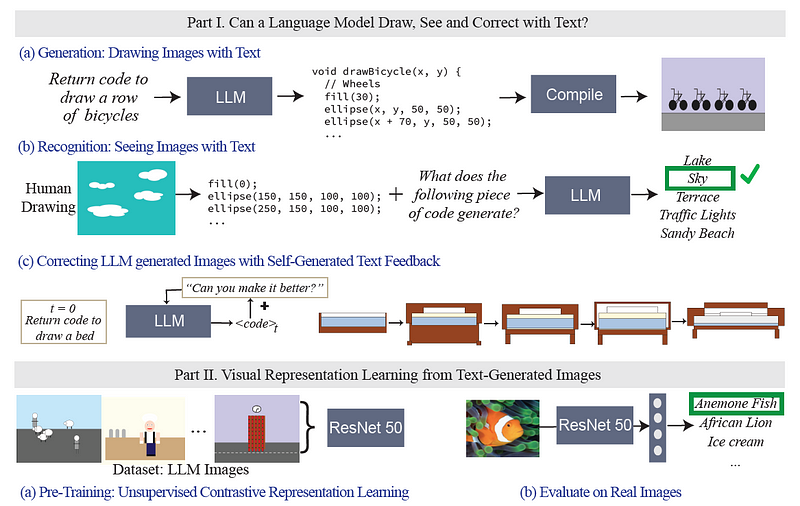
2.3 Bigger Models, Bigger Alignment
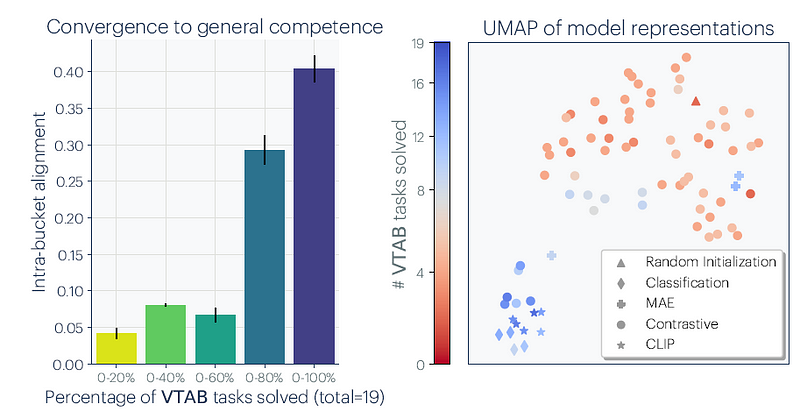
The degree of alignment among models correlates with their scale. For instance, larger models trained on CIFAR-10 classification exhibit greater alignment than smaller counterparts. This trend suggests that as models continue to scale into the hundreds of billions of parameters, their alignment will only increase.
3. Why are AI Models Converging?
In the training of AI models, several factors contribute to their convergence:
3.1 Tasks are Becoming General
As models are trained to tackle increasingly general tasks simultaneously, their solution space narrows and becomes more constrained. Greater generality entails learning data points that align more closely with reality.
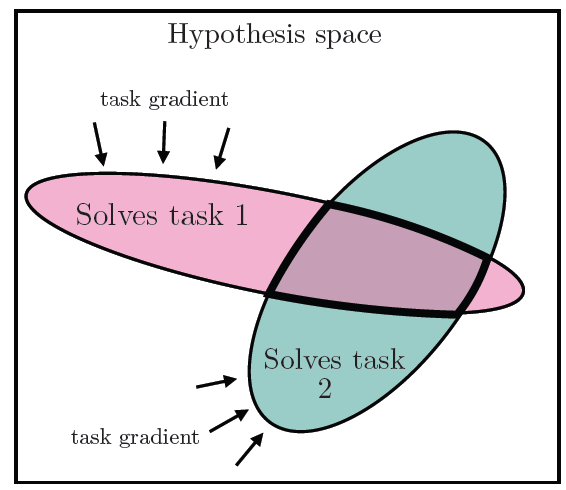
The paper articulates this phenomenon as "The Multitask Scaling Hypothesis," positing that fewer representations are competent for N tasks than for M < N tasks. Hence, as we train more general models across expansive datasets, the solution space becomes increasingly constrained.
3.2 Models are Getting Bigger
As models expand in capacity through advanced architectures, larger datasets, and more intricate training algorithms, they tend to develop representations that resemble one another more closely.
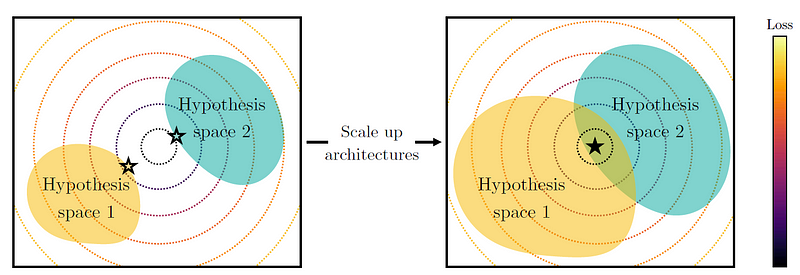
While the paper does not provide definitive proofs for what they term the "Capacity Hypothesis," which states that larger models are more likely to converge on a shared representation, it stands to reason that larger models have more potential for discovering mutual solution spaces.
3.3 The Simplicity Bias
Consider training two large-scale neural networks on separate tasks: one for recognizing faces and the other for interpreting facial emotions. Initially, these tasks seem unrelated, yet it is plausible that both models would converge on similar representations of facial features, as both tasks require identifying key facial landmarks.
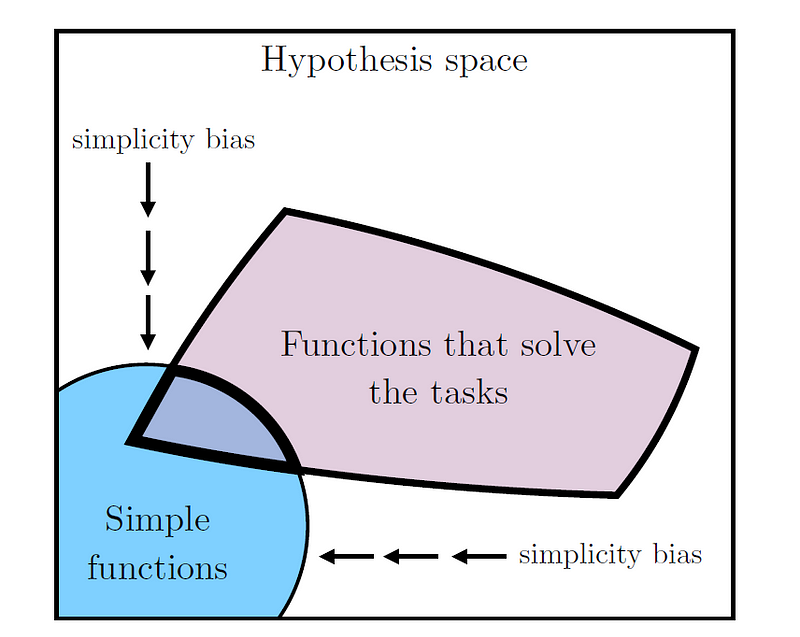
Research indicates that deep neural networks tend to favor simpler solutions, a tendency referred to as "The Simplicity Bias." The paper concludes that deep networks are inclined to find simple fits to data, and this inclination strengthens as model size increases. As a result, larger models are expected to converge to a more limited solution space.
4. Implications of This Convergence
What are the implications if AI models are indeed converging? Primarily, it suggests that data across different modalities may be more beneficial than previously considered. For instance, fine-tuning vision models with pre-trained LLMs or the reverse could yield unexpectedly favorable outcomes.
Another key implication is that "scaling may reduce hallucination and bias." As models scale, they can learn from larger and more diverse datasets, enhancing their understanding of the world and enabling them to produce more reliable and less biased outputs.
5. A Pinch of Salt
While the arguments presented in the paper are compelling, they do have limitations. The authors assume a bijective projection of reality, suggesting that one real-world concept Z can have projections X and Y that are learnable. However, certain concepts may be uniquely inherent to specific modalities. For example, language can convey emotions or ideas that images cannot, and vice versa.
Moreover, the focus remains primarily on two modalities: vision and language. The assertion that "AI models are converging" applies only to multi-task AI models, not specialized ones like ADAS or sentiment analysis models.
Lastly, although the paper demonstrates that the alignment among models increases, it does not conclusively show that their representations become identical. The alignment scores for larger models are indeed higher, but a score of 0.16 out of 1.00 leaves some questions unanswered.
Join over 1000 individuals exploring topics in Python, ML/MLOps/AI, Data Science, and LLMs. Follow me and check out my X/Twitter for daily updates.
Thanks for reading, — Hesam
References: [1] Liu, H., et al. "Visual instruction tuning." In NeurIPS, 2023. [2] Sharma, P., et al. "A vision check-up for language models." In arXiv preprint, 2024. [3] Shah, H., et al. "The Pitfalls of Simplicity Bias in Neural Networks," 2020. [4] A brief note on Simplicity Bias. [5] "Deep Neural Networks are biased, at initialization, toward simple functions."